
Unit tests are a staff software engineer's secret weapon.
As an aging software engineer, I've noticed that seniority is generally correlated with the amount of code you "own." You may not write more code as you get promoted more (my experience is that you actually write less code and more English), but you will be tagged in a growing number of code reviews as the "legacy" codebase grows and you inherit the work of your departing colleagues.
That's why you must insist on unit tests. You must unit test your own code, and you should make reasonable efforts to encourage colleagues to include them in their pull requests / diff stacks / change lists. They're written once, but add value to all your colleagues for years to come. Unit tests give you confidence to build ambitious features and make sweeping refactors. Unit tests will save you when you have to clean up the crusty parts of the code that nobody remembers committing.
Unit tests for large language model applications
When it comes to unit testing, LLM apps are no exception. When viewed as software, most LLM applications boil down to calls of completion(prompt: String): String and semantic_search(query: String): List[String] combined with some API integrations to access knowledge sources and output results as an article / e-mail / slideshow / SQL / visualization.
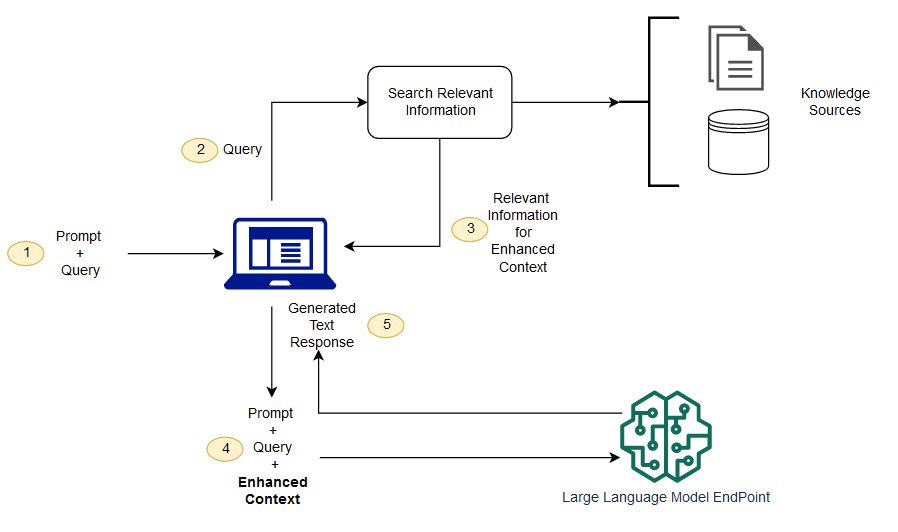
LLM apps are no exception to this rule. If we took the AI out of the picture, we'd be left with a search engine, some query API integrations, and a data / file format converter. All of these components have existed before LLMs took off and the most successful have good test suites providing a confident amount of code coverage.
When you add LLMs back into the picture, a few new issues arise.
1. LLMs are too big / proprietary and can't be run in continuous integration
This is a valid concern. The most popular LLMs today (OpenAI's GPT series) are closed-source, and even if they were available they would be too large to run as part of most continuous integration systems.
2. Using OpenAI's APIs during tests can be expensive
With GPT-4 coming in at $0.03-0.06 / 1k tokens, costs can quickly add up and you might find yourself asking whether you really need to invoke GPT-4 during your tests. In fact, if you use an actual LLM during your tests you might find yourself suffering from the next issue...
3. LLMs are stochastic and might cause flaky tests
Many bug report templates ask for specific reproduction instructions and will be dismissed as "no-repro" if they are not provided or fail to reproduce the bug. Engineers hate heisenbugs and flaky (randomly failing) tests. To avoid flaky tests, doing the same thing (running the test) twice should produce the same results.
Unfortunately, when it comes to LLMs randomness is considered a feature. If LLMs generated the same response every time, their creative applications would be severely limited. Without additional intervention, doing the same thing (running a LLM) twice should produce different results. What an unfortunate state of affairs.
Introducing Stubidity
At Blueteam AI, we write a lot of code integrating with LLMs. And as good engineers, we demand that unit tests accompany the code we write so that we can confidently ship features without causing regressions. In order to solve these problems outlined above, we built stubidity in order to provide stub implementations of OpenAI for use during tests.
Stubidity runs a stub API server which implements the same HTTP API as OpenAI and has support for both completions and chat completions as well as their streaming variants. It's open source, so you can host it yourself inside your CI suite. Or for added convenience, you can use our free public offering by modifying your OpenAI base URL during tests.
$ curl \
-X POST \
-H "Authorization: Bearer foo" \
-H "content-type: application/json" \
https://fmops.ai/api/v1/stub/openai/v1/chat/completions \
-d '{"model": "gpt-3.5-turbo", "messages": [{"role": "user", "content": "Tell me a joke"
}], "stream": true}'
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"role":"assistant"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":"Why"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":" was"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":" the"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":" math"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":" book"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":" sad"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":"?\n\n"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":"Because"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":" it"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":" had"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":" too"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":" many"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":" problems"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{"content":"."},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-6zwEy96ojYcDRcdNX8f4L9fu95CaJ","object":"chat.completion.chunk","created":1680219904,"model":"gpt-3.5-turbo-0301","choices":[{"delta":{},"index":0,"finish_reason":"stop"}]}
data: [DONE]After integrating, you gain the following benefits.
Deterministic responses
Stupidity is doing the same thing twice and expecting different results.
- not Albert Einstein
When you send the same request twice, you'll get the same response back! No more flaky tests; your engineers and testers will thank you (and also know why the math book is sad).
Decoupling from OpenAI
OpenAI's API latency can vary wildly over the course of the day. Using Stubidity decouples you from this (and saves you a network roundtrip) so your test always run quickly.
Cost savings
Stubidity's responses are hardcoded; say goodbye to expensive API calls and energy wasting GPU cycles on transformer forward-passes. Our unit test suite uses around 40k tokens and is run roughly 10 times a day, so compared to invoking LLM APIs stubidity is saving us about $12 / day. That's in addition to all the engineering hours and morale saved from troubleshooting flaky LLM tests.
Conclusions
Stubidity is a young project, but we've found it quite valuable already. We're happy to share it with the community and hope you find it useful as well.
Do you need Stubidity to do something it doesn't currently do, would like to work on open source software, or are curious about the Elixir programming language? You are personally invited to come help: Join our Discord and say hi!
Developing LLM applications? Take a look at blueteam.ai; a monitoring and security platform built specifically for LLMs.