Overview
- Added Redis and Chroma clients to open-source vector benchmarking project VectorDBBench
- Ran local benchmark tests and found the following key takeaways:
- If memory isn't an issue, Redis performs extremely well.
- For ease of use, Chroma's API and setup are user friendly. Its load duration and recall were not the best performing but it is still practical for most cases and will likely perform better when running in-process.
- PgVector has the tradeoff of perfect recall for a sacrifice in speed and performance. However, Redis-Flat outshines it in performance (but not memory usage).
Intro
The options for vector databases can be a little overwhelming. There’s open source options from widely deployed databases like Redis and Postgres (utilizing the PgVector library), newer open source projects like Chroma, and also paid services like Pinecone, Zilliz, Milvus and Qdrant.
Vector databases can run in-process or independent of the application using them, utilize either IVFFlat or HNSW to store the vectors, and store the data either in-memory, on disk, or a hybrid of the two. Some advantages and disdvantages to these differences:
- An advantage to using an in-process database is improved performance, since the data is transferred within the same memory space and not across sockets.
- A disadvantage to an in-process database is the inability to independently scale components (since it is using the same memory space as the application it runs in).
- HNSW gives improved search performance over IVFFlat at the expense of build time, index size, and recall (search accuracy).
- IVFFlat is slower to search than HNSW, uses less memory, builds faster, and has greater search accuracy than HNSW.
- Redis and Postgres are widely deployed (and due to this have a potentially lower technical cost).
- In memory storage is fast and costly, whereas on-disk is cheap and slower.
We set out to test open-source databases to figure out differences in performance and potential cost. The ones we tested are listed here along with some of their key characteristics:
- Redis operates completely in memory and has capability to use both HNSW and IVFFLat. It does not run in-process. Since it does not utilize disk, perfomance is high but so is the cost.
- Chroma runs in-process or client-server and supports HNSW. It utilizes both memory and disk.
- PgVector only supports IVFFlat at the time of this writing, it does not run in process, and it utilizes memory and disk.
We wanted to test for performance, specifically queries per second, latency, and load duration.
We wanted to know which open-source vector database should we use?
We started by looking to see if somebody else had already done some testing that answered this question (because it’s really nice when somebody else has figured it out already).
Two benchmarking test results were close to what we were looking for, but nothing fit our needs exactly.
Jina Benchmarks
The first relevant results are some benchmarking done by Jina that included Redis, SQLite, ElasticCloud and a few others. The tests used 128 dimension vectors but also seem reliable and well done.
Their conclusion:
If your data set is large but still fits in memory, go with Redis or AnnLite. If your dataset does not fit in memory, and you do not care much about the speed of nearest neighbor search, you can use SQLite as storage.
Otherwise, Weaviate, Qdrant and Elasticsearch are good options.
Based on this information we decided to leave SQLite out of the testing since speed is certainly a factor.
Here’s a graphic overview of Jina’s tests. It’s qps plotted against the fraction of true nearest neighbors found, on average over all queries using a dataset of 1M 768 dimensional vectors. Up and to the right is better.
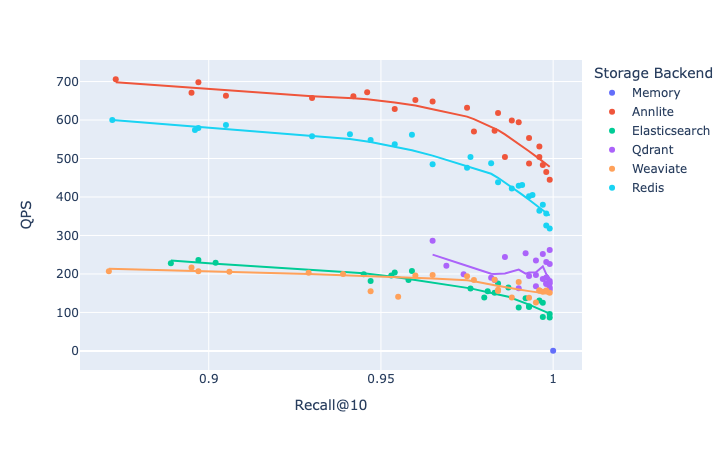
Jina's benchmarks did not include Postgres and Chroma, and they were missing a comparison of Redis's HNSW and IVFFlat settings, so we kept looking.
Zilliztech Benchmarks
The other notable benchmarking we found was an open source project called VectorDBBench which can be found here (referred to after this point as VDB).
VDB measured a lot of the things that we wanted to measure when comparing databases. Here’s an example of their nice front end comparing queries per second:
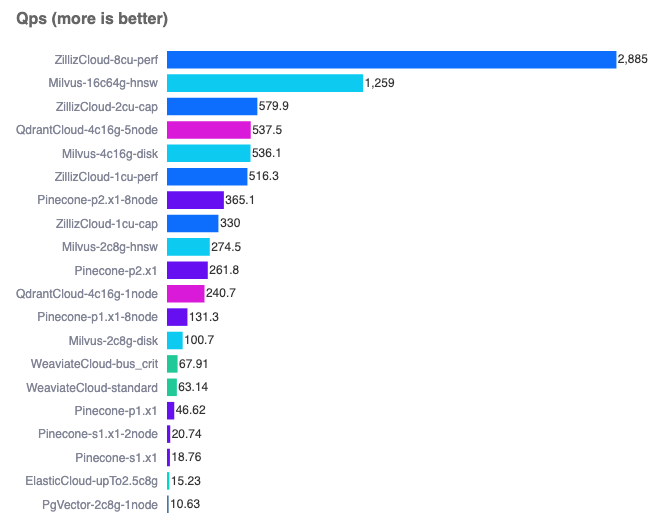
(Note PgVector using IVFFlat at the bottom).
Here’s a quote from their github about their hardware used for testing:
All standard benchmark results are generated by a client running on an 8 core, 32 GB host, which is located in the same region as the server being tested. The client host is equipped with an Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz processor. Also all the servers for the open-source systems tested in our benchmarks run on hosts with the same type of processor.
VDB measures queries per second, latency and recall in the performance cases, as well as search filtering performance, capacity and queries per dollar.
VDB has a bunch of different vector sets to use for testing but unfortunately as of the time of this writing it does not have a 1536 dimensional dataset (openAI embedding’s ada-002 vector size). We figured that we could get approximate results with their existing data set. (Update: VDB added a 1536 dimension dataset right before publication)
Zilliz's tests were missing a few open source databases that we wanted tested (like Redis and Chroma) so we set out to add them.
Databases Tested
We added the following clients to VDB for testing
Already built into VDB:
- Pinecone
- ZillizCloud
- ElasticCloud
- Weaviate
- Milvus
- Qdrant
- PgVector
We intended to test out SQLite using the sqlite-vss package but we decided Jina's benchmark (mentioned above) leads to the conclusion that SQLite’s vector storage and retrieval is pretty slow in comparison to other databases. VDB may add sqlite-vss in the future and its performance can be further evaluated.
Testing Methodology
The basic layout for our local testing was for our intern to create a docker container on their M1 16gb Mac that ran the database being tested, and use VDB locally to get approximate benchmarks for some of the free databases while the great folks at VDB incorporated our pull requests and ran tests on their standardized machine.
We ran into some hardware limitations. The Mac air that was used for testing really struggled through some of these tests, but overall the goal was to produce some quick apples to apples comparisons of the following databases / libraries:
- Redis-Flat
- Redis-HNSW
- Chroma
- PgVector
Tests
After we created and added the clients for Redis and Chroma, we ran some preliminary tests using the built in 1M 768 dimension Cohere dataset. We ran into some time-out issues in these tests (discussed in "Issues Encountered During Benchmarking" section below).
To resolve the issues in a way that could still allow the databases to be compared via VDB on our hardware, we shortened the data set size to 300k and ran some tests. These are the results:
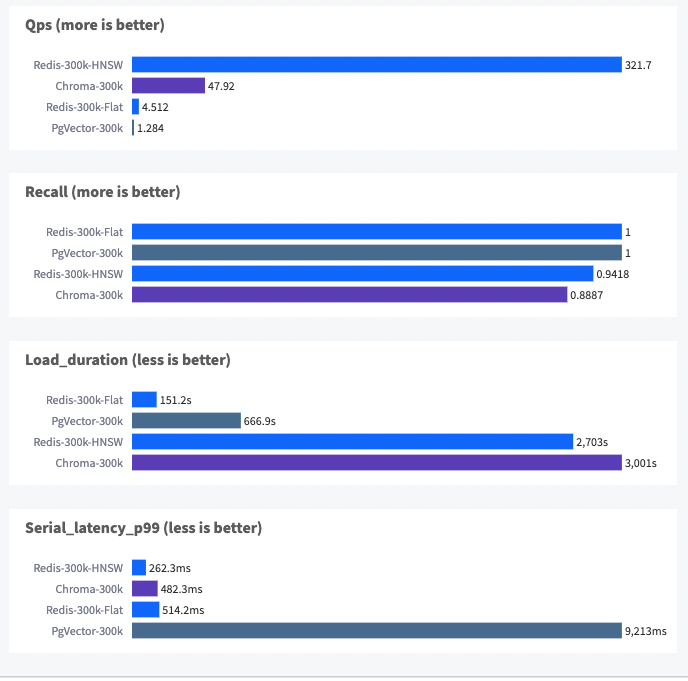
Some observations about these tests:
- Chroma has the lowest recall and highest load duration
- HNSW takes a lot longer to load than IVFFLat, but results in better search performance.
- PgVector's latency is high
Issues Encountered During Benchmarking
When we ran initial tests on the 1M dataset, these are some of the issues we encountered:
- Redis-Flat timed out during recall testing.
- Chroma also timed out during recall testing.
- Redis-HNSW took exponential time to build and timed out around half a million vectors during the load phase. Every 100,000 vectors that were added took twice as long as the previous 100,000. The load phase timeout in VDB is 2.5 hours.
- Chroma running in client-server mode was hit and miss in terms of functionality. A lot of the time the database would unexpectedly terminate the connection while loading. The load time was also slow and would sometimes time out.
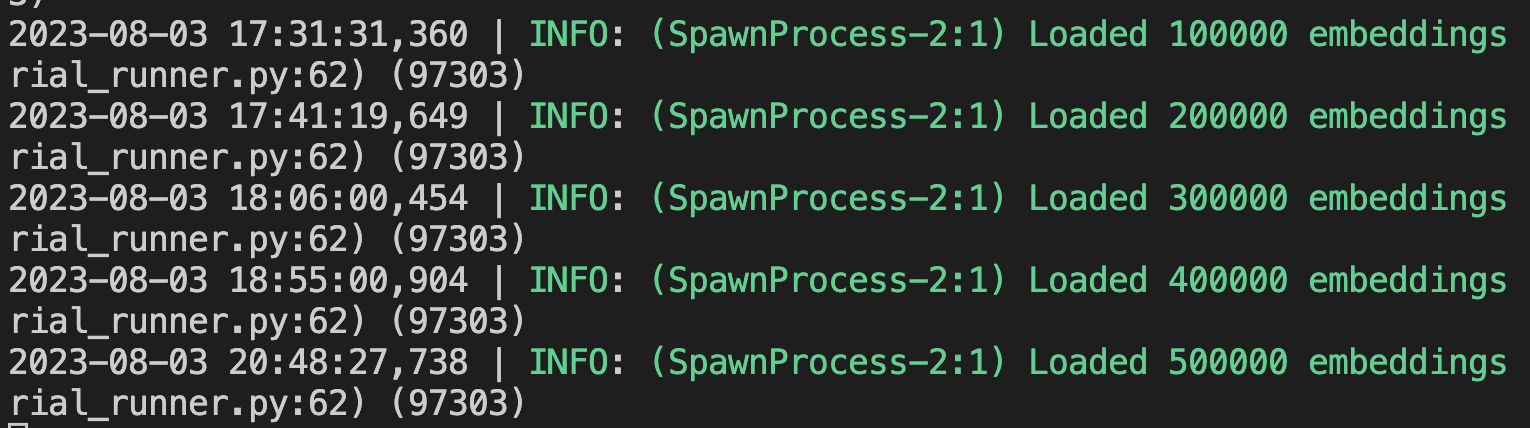
Redis took a long time to build the HNSW index, despite tweaking the parameters down fairly low in some of the tests. This could definitely be a hardware limitation or operator error, as could all of the other issues. Here's a screenshot of the database load times:
Conclusion
Redis HNSW seems like a clear winner (on this hardware, with this setup, for this small size dataset). Redis runs in memory, and assuming that we had enough memory we could get these speeds in a full scale deployment. This confirms the results previously mentioned by Jina. Assuming memory isn't a problem, Redis is fast.
As the maintainers of the VDB project run tests on their machines, comparisons for paid database services against open source options like Redis, Chroma and Postgres will be available.