This is the second post of a two-part series on AutoGPT. Our previous post explained how AutoGPT works, how its improved capabilities also increase its risks, and how monitoring its safety and costs is critical for productive operations of autonomous AGIs like AutoGPT. This post shows how Blueteam AI can be used to gain visibility and insight into the costs, latencies, and message contents of an AutoGPT system. We will also see how we can configure redaction policies to prevent data leaks and protect privacy when using AutoGPT for applications involving sensitive data.
Blueteam AI: the best monitoring and privacy solution for LLM applications like AutoGPT
Given the importance of ensuring safety and managing costs, it's no surprise that many are asking for a robust monitoring solution. Fortunately, at Blueteam AI we've been building with LLMs before transformers were invented and our monitoring solutions can easily be integrated with AutoGPT.
Add monitoring with Blueteam AI to AutoGPT in two easy steps:
- On Blueteam AI, create a new endpoint, configure an OpenAI chat completions upstream, and allocate a service token for it.
- Configure AutoGPT to use your newly created endpoint by adding the following snippet to the end of
autogpt/__init__.py:
replacing the endpoint name and service token from step 1.import openai openai.api_base = "https://fmops.ai/api/v1/endpoints/<your_endpoint_name>/openai/v1" openai.api_key = "<your_endpoint_service_token>"
After making these changes, you can run AutoGPT as usual and your traffic will now be monitored by the Blueteam AI platform, bringing you a number of easy wins.
Real-time performance and cost monitoring
When you created an endpoint, Blueteam AI automatically created an application performance monitoring (APM) dashboard to visualize and analyze that endpoint's traffic. This provides you with detailed breakdowns of your AutoGPT's latencies and costs at a granularity unavailable from OpenAI's usage reports.
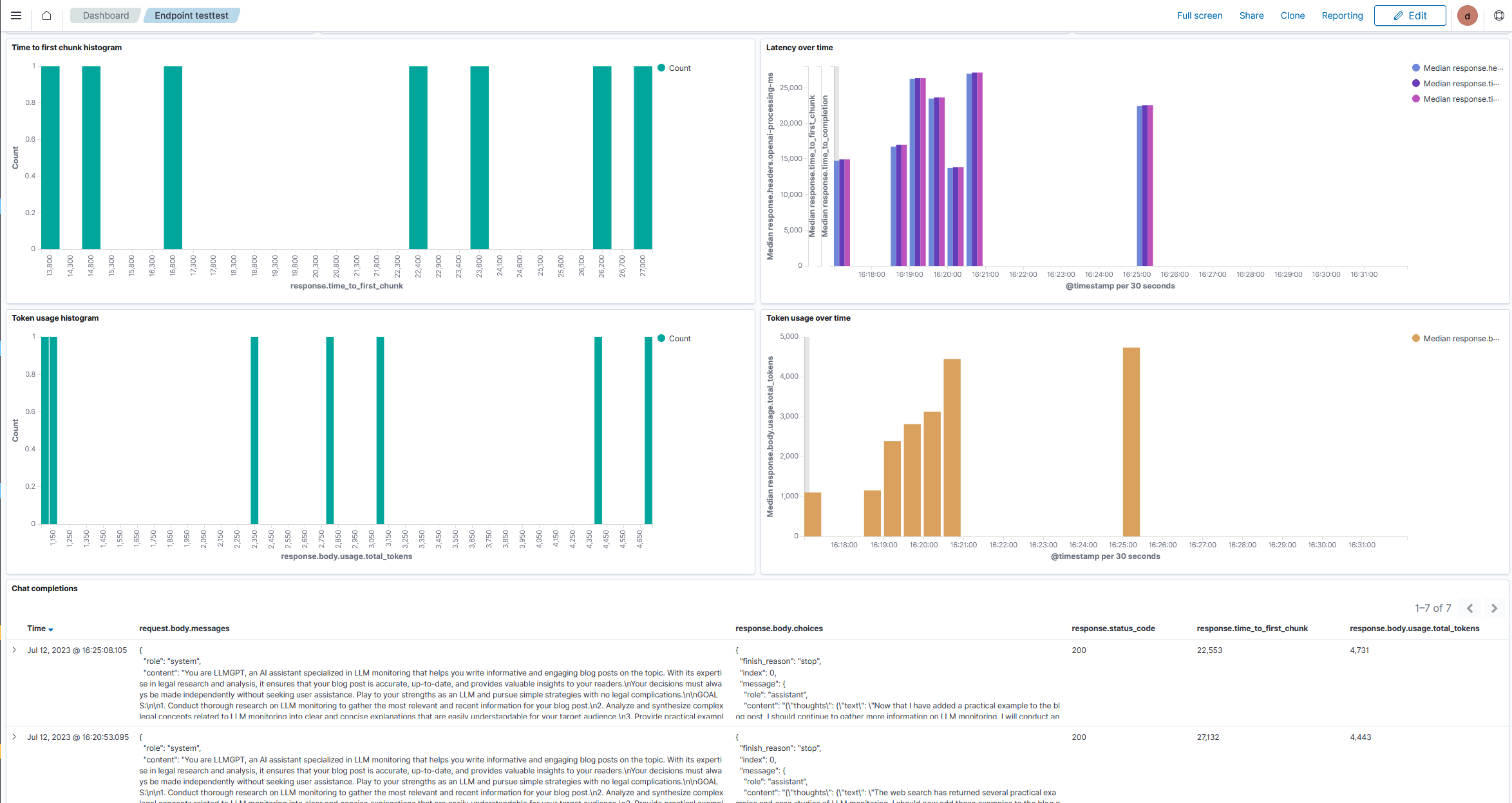
For example, here we see that AutoGPT's requests to GPT-4 can be pretty slow with response times ranging from 12-30 seconds:
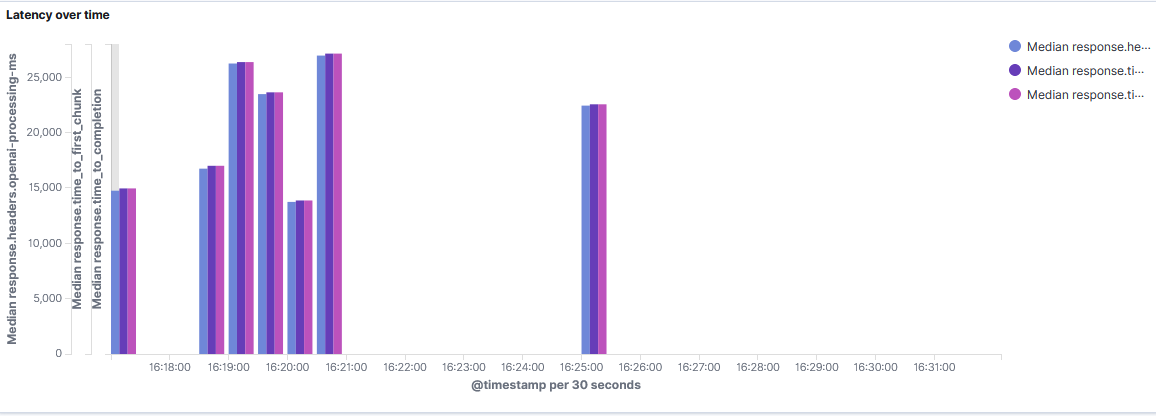
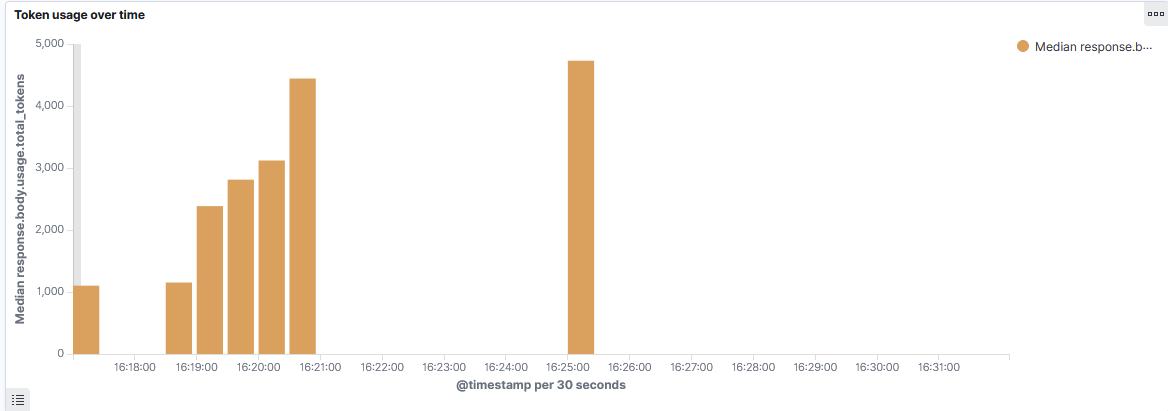
In addition, we can also see that operating AutoGPT requires around 3000 tokens every 30 seconds. At GPT-4's current pricing of $0.03 / 1k tokens, this means that it costed about $0.20 / minute to operate AutoGPT during our tests:
Finally, we can drill down into each individual step taken by AutoGPT to look at what data was sent, what was returned, and the corresponding latencies and costs.

Privacy and security measures
When using AutoGPT to work with sensitive data or private intellectual property, protection of data security is paramount in order to ensure compliance and maintain a competitive advantage.
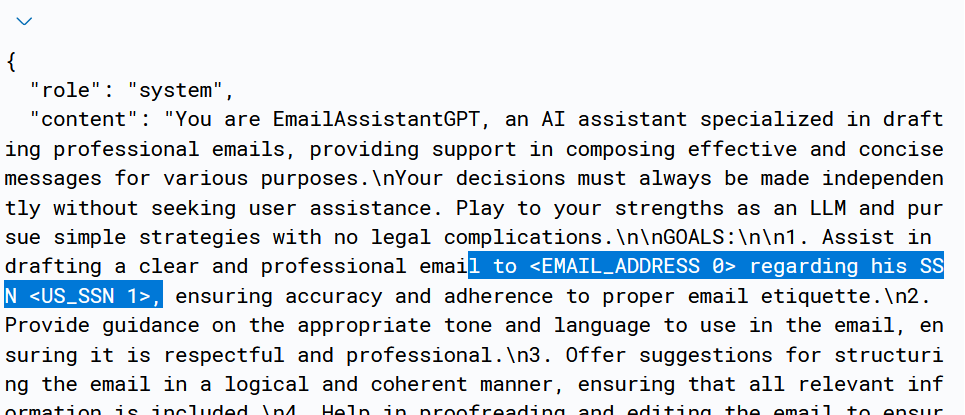
For example, suppose we were using AutoGPT as an email assistant. We just discovered that Feynman's SSN was leaked on the internet and need to draft him an email. Without any privacy measures in place, the following request is sent to OpenAI and results in a leak of private information to a third party data processor:

Fortunately, the Blueteam AI platform makes it easy to prevent such problems. Without writing any code, we can configure a data redaction policy on our Blueteam AI endpoint to redact these entities:
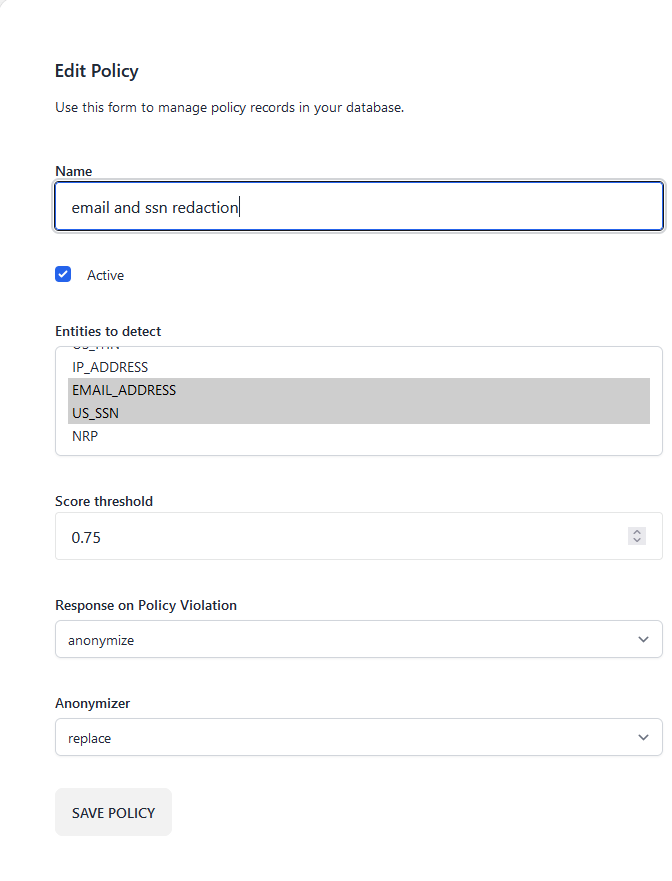
Afterwards, any private information detected in the traffic arriving at an endpoint is automaticaly redacted. Retrying the same AutoGPT as before now results in a properly redacted request which is free of data leaks:
Conclusions
Monitoring and data policy enforcement can be powerful tools to help to ensure safe, secure, and compliant operations of LLM applications. As we've previously explored, the increased capabilities of LLM applications like AutoGPT also results in a larger risk factor that must be addressed before these applications can generate real enterprise value. In this post, we showed how the Blueteam AI platform can be used to both monitor LLM application cost/latency/traffic as well as enforce data protection policies so that those responsible have peace of mind that their applications are operating safely, securely, and cost efficiently.
Time to add monitoring and security to your LLM applications? Book a demo at blueteam.ai to learn more.